Quality Systems Services





Copyright (c) Quality Systems Services 1995 - 2019
Other services...
In addition to the NameBase service we offer a number of other data cleaning and reporting services. These include data audits, database merging, address enhancement, match coding, de-duplication, mailsorting, general data reporting, datacapture and database consultancy services.
De-Duplication is a two stage process, first the auditable identification and reporting on duplicate data in your database using purpose built in-house software. Secondly the reporting, removal or consolidation of duplicate data to your requirements.
The de-duplication software has been designed to identify duplicate data without automatic duplicate removal. This is so you can choose to report on or retain any extra data associated with the duplicates. For example you may wish to post process the duplicate matching results in order to remove duplicate addresses while retaining any data that might be held in related database tables.
Duplicates can be identified using up to 255 separate client defined analysis keys. The software allocates an auditable status code to any duplicate data telling you which data is duplicated and why.
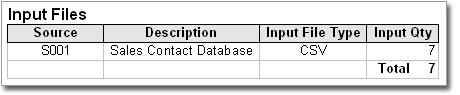
A typical de-duplication report would contain a variety of information such as how many files were supplied for de-duplication, a description of each source file and how many records were processed...
De-Duplication is a two stage process, first the auditable identification and reporting on duplicate data in your database using purpose built in-house software. Secondly the reporting, removal or consolidation of duplicate data to your requirements.
The de-duplication software has been designed to identify duplicate data without automatic duplicate removal. This is so you can choose to report on or retain any extra data associated with the duplicates. For example you may wish to post process the duplicate matching results in order to remove duplicate addresses while retaining any data that might be held in related database tables.
Duplicates can be identified using up to 255 separate client defined analysis keys. The software allocates an auditable status code to any duplicate data telling you which data is duplicated and why.
A typical de-duplication report would contain a variety of information such as how many files were supplied for de-duplication, a description of each source file and how many records were processed...
You would see counts of duplicates matched between the source files...
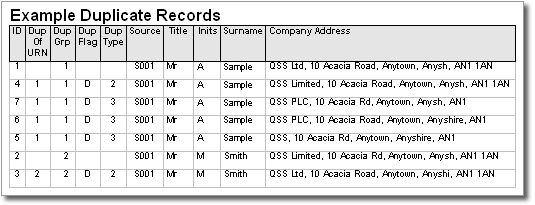
You would see counts of duplicates matched for each of the analysis keys you specified...
And ultimately you would be able to choose what you wish to do with the duplicate data, for example you could get the fully tagged result data returned to you for in-house post processing...
Duplicate identification can be improved by using techniques such as...
Match-Coding which takes your surname, address and company name data and produces phoneticly coded versions to enable dissimilar database records to be matched by the de-duplication software.
Data variability creates quite a challenge to successful duplicate identification. Duplicates are often caused by minor differences between data rows. Differences such as multiple occurrences of the same character and variations in vowel groups that are phonetically identical, that is, they sound alike but are in fact different such as 'ee', 'ei', and 'ea' in the words Reed, Reid and Read. QSS match codes enable the matching of dissimilar data such as this.
The match codes are generated by utilising techniques such as word removal or replacement using dictionaries of address and company name words. Along with other processing such as punctuation removal and the phonetic character reduction already mentioned. Different match code types are created depending on the data supplied, surname, address and company name match code variants for example.
Match-Coding which takes your surname, address and company name data and produces phoneticly coded versions to enable dissimilar database records to be matched by the de-duplication software.
Data variability creates quite a challenge to successful duplicate identification. Duplicates are often caused by minor differences between data rows. Differences such as multiple occurrences of the same character and variations in vowel groups that are phonetically identical, that is, they sound alike but are in fact different such as 'ee', 'ei', and 'ea' in the words Reed, Reid and Read. QSS match codes enable the matching of dissimilar data such as this.
The match codes are generated by utilising techniques such as word removal or replacement using dictionaries of address and company name words. Along with other processing such as punctuation removal and the phonetic character reduction already mentioned. Different match code types are created depending on the data supplied, surname, address and company name match code variants for example.